
MySQL이라고 부르는 것은 MySQL 서버라고 부를 수 있다.

서버 안에는 두뇌의 역할을 하는 MySQL 엔진이 있고
여러 개의 손발의 역할을 담당하는 스토리지 엔진으로 구성이 되어 있다.

이 두뇌의 역할을 하는 MySQL 엔진과 스토리지 엔진은 핸들러 API를 통해서 서로 통신을 주고 받는다.

쿼리의 실행 과정을 통해서 MySQL 아키텍처를 살펴보자
위와 같이 두 개의 테이블을 준비했고 하나의 article 테이블이 members의 아이디를 외래키로 참조하는 형태이다.

article 테이블에서 릭으로 시작하는 콘텐츠를 모두 검색하고 작성자의 이름을 가져오기 위해서 members 테이블에 조인을 하는 형태의 쿼리를 날리는 실행 과정을 통해 알아보자

사용자가 쿼리를 날리게 되면 쿼리 파서가 먼저 요청을 수행한다.

쿼리 파서는 SQL 문장을 트리의 형태로 파싱을 하게 되는데, 이 트리 안에 들어 있는 각각의 요소들은 MySQL이 인지할 수 있는 최소한의 단위인 토큰이라고 부르는 단위로 파싱이 된다. 이 때 SQL 구문의 문법적인 오류가 있는지 검사하고 예외가 있다면 사용자에게 예외 메세지를 반환하는 역할도 함께 한다.
정리
- Parser가 만든 트리를 기반으로 SQL 구문의 유효성 검증 수행
- 각 토큰의 테이블, 컬럼, 프로시저 등이 존재하는지 확인
- 객체의 접근 권한 확인

다음으로 전처리기에게 파스 트리가 전달이 된다.

전처리기는 예약어를 제외한 토큰을 검사를 해서 실제로 데이터베이스 안에 객체가 존재하는지 그리고 그 객체의 사용자가 접근을 할 수 있는지, 권한 같은 것들을 검증을 하는 역할을 수행한다.

검증을 마친 파스 트리는 옵티마이저에게 전달된다. 옵티마이저는 이러한 파스 트리를 실행 계획으로 바꾸는 역할을 한다.

실행 계획을 확인해 보자
1) id
먼저 아이디가 동일한 두 개 row가 있기 때문에 두 테이블은 조인을 하는 형태로 실행이 된다는 것을 의미한다.
2) table
article 테이블과 members 테이블을 읽는다는걸 알 수 있다. article 테이블을 먼저 읽어서 드라이빙 테이블로 선정하고 member 테이블은 나중에 읽는 드리븐 테이블로 선정을 한다는 것을 알 수 있다.
3) type
두 개를 인덱스 풀 스캔과 조인을 할 때 기본키를 참조하는 형태로 데이터를 읽어온다는 것을 알 수 있다.
4) key
두 테이블 모두 기본키를 사용해서 테이블을 읽어 온다는 걸 알 수 있다.
이처럼 옵티마이저는 쿼리를 재작성하거나 테이블 스캔 순서를 결정하고 인덱스를 사용한다면은 어떤 인덱스를 사용할지 선택을 하면서 최적의 쿼리를 실행하기 위해서 실행 계획을 수립하는 역할을 한다. 그리고 옵티마이저는 비용 기반 최적화와 규칙 기반 최적화로 나눌 수 있다. 비용 기반 최적화는 MySQL에 존재하는 다양한 통계 정보를 활용해서 실행 계획을 수립하고, 규칙 기반 최적화는 동일한 SQL이라면 항상 동일한 실행 계획을 수립을 하게 된다. MySQL을 포함해서 대부분의 RDBMS들은 비용 기반 최적화 방식으로 옵티마이저가 동작한다.
정리
- 쿼리를 최적으로 실행하기 위한 실행 계획 수립
- 쿼리 재작성, 테이블 스캔 순서 결정, 사용할 인덱스 선택
- 비용 기반 최적화, 규칙 기반 최적화

다음으로 옵티마이저가 만들어낸 실행 계획은 실행 엔진에게 전달된다.

실행 엔진은 실행 계획을 토대로 스토리지 엔진과 통신을 해서 위와같이 데이터를 읽어오는 작업을 수행한다. 드라이빙 테이블인 article 테이블에서 먼저 읽어오고 members 테이블에 조인해서 데이터를 하나씩 읽어온다.
정리
- 실행 계획대로 쿼리를 수행
- 핸들러 API를 사용해서 스토리지 엔지과 지속적으로 통신

실행 엔진은 스토리지 엔진과 통신하는데 스토리지 엔진은 실행 엔진의 요청을 처리하기 위해서 디스크로부터 데이터를 읽기, 쓰기 작업 하는 것을 주된 목적으로 역할을 수행한다. 이 때 스토리지 엔진은 MySQL 엔진과 다르게 여러 개를 동시에 사용할 수 있다는 특징이 있다.
정리
- 실행 엔진의 요청을 처리하기 위한 디스크로부터 데이터 읽기/쓰기
- 여러 개를 동시에 사용 가능

MySQL 엔진은 앞서 살펴본 파스 트리, 전처리기, 옵티마이저 등으로 이루어져 있다.

InnoDB 스토리지 엔진은 트랜잭션, 버퍼풀, 클러스터링 인덱스, MVCC, 외래키, 데드락 감지 등의 특징이 있다.
(MyISAM은 MySQL 8.0 버전 이후부터 InnoDB 스토리지 엔진을 기본 스토리지 엔진으로 사용한다. 차이점은
MyISAM은 트랜잭션을 지원하지 않고, InnoDB는 트랜잭션을 지원한다. 이번에는 InnoDB 스토리지 엔진만 살펴볼 예정이다.)
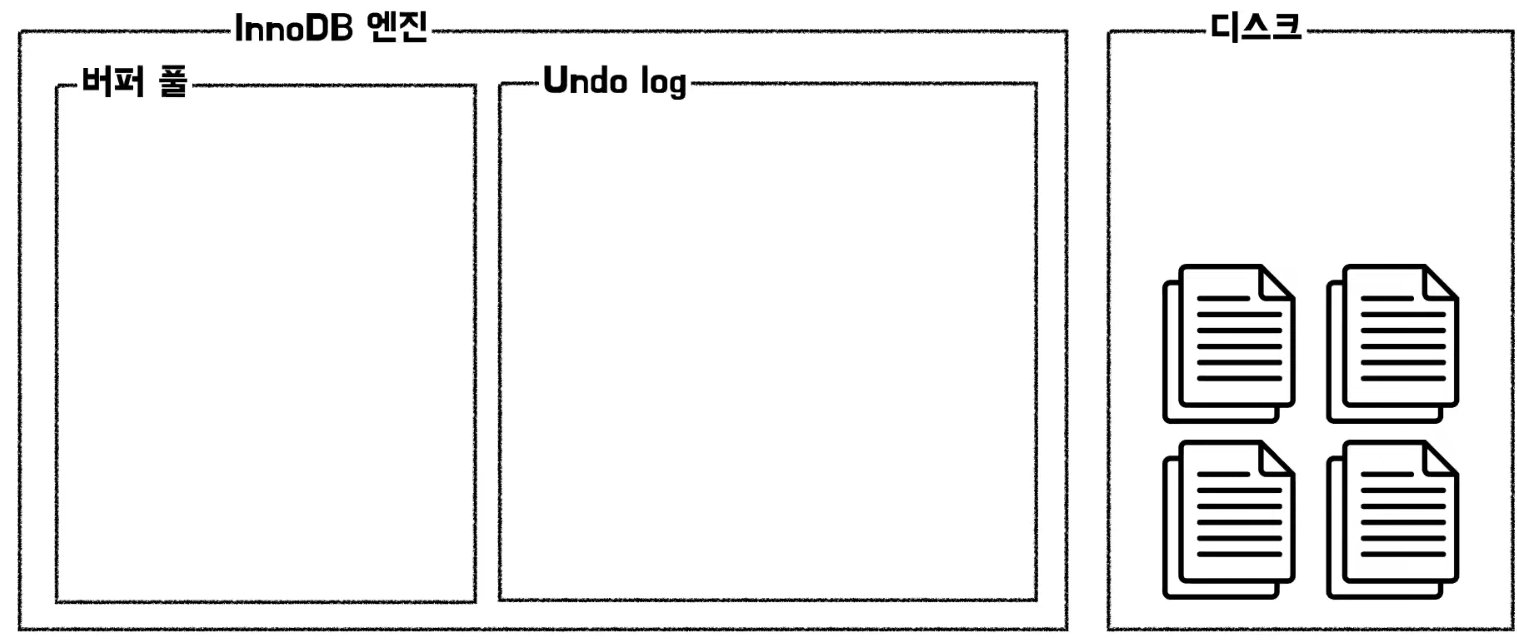
InnoDB 엔진을 트랜잭션의 관점에서 쿼리 수행 과정으로 알아보자
InnoDB 엔진과 파일을 읽어오기 위한 디스크가 있고, InnoDB 엔진 안에는 버퍼 풀과 Undo log로 구성되어 있다.
SET GLOBAL TRANSACTION ISOLATION LEVEL REPEATABLE READ;
START TRANSACTION;
INSERT INTO members(nickname) VALUES ('릭');
먼저 트랜잭션 격리 레벨을 REPETABLE READ로 설정을 하고 트랜잭션을 시작한다. 그리고 members 테이블에 닉네임이 릭인 데이터를 삽입했다.

디스크를 보면은 디스크에 아이디가 6이고 닉네임이 릭인 데이터가 잘 들어갔고 버퍼 풀에도 동일한 데이터가 들어가 있는 모습을 볼 수 있다. 이것은 InnoDB 엔진이 버퍼 풀의 데이터를 캐싱했다는 것을 알 수 있다.
UPDATE member SET nickname='로마' WHERE id=6;
COMMIT;
그 다음 방금 삽입한 데이터의 닉네임을 로마로 한 번 바꾸고 커밋까지 진행하였다.

로마로 변경한 데이터가 버퍼 풀에 먼저 반영되었고 이전의 데이터인 릭인 데이터는 Undo log에 추가가 된 모습을 볼 수 있다. 그리고 이 때 디스크에 있는 닉네임은 물음표로 표시했는데, 이유는 InnoDB 엔진이 버퍼 풀에서 쓰기 작업을 지연시키는 쓰기 버퍼링이라는 기능이 있기 때문이다. 만약에 쓰기 작업이 지연되어 있는 상태라면 디스크에는 변경되기 이전인 릭이 저장이 되어있는 상태일 것이고, 쓰기 작업이 일괄적으로 처리가 된 상태라면 로마가 저장되어 있을 것이다.
Undo log에 트랜잭션 아이디라는 컬럼으로 방금 실행한 트랜잭션의 아이디가 11번이었다는 걸 알 수 있다.
트랜잭션 아이디는 순차적으로 증가하는 값을 가지기 때문에 트랜잭션 아이디 11보다 작은 트랜잭션을 조회하면 어떤 결과가 나올까?
SELECT * FROM members WHERE id=6;

트랜잭션 아이디가 11보다 작다는 것은 11번 트랜잭션보다 먼저 시작한 트랜잭션이란 것을 의미한다. 그래서 11번 트랜잭션이 변경하기 이전 데이터를 읽어와야 한다.이 때는 Undo log에서 변경 되기 이전에 데이터를 읽어오게 된다.
반대로 아이디가 11번보다 큰 경우에는 어떻게 될까?

11번보다 큰 경우 11번 트랜잭션은 이미 커밋을 했기 때문에 Undo log가 아니라 버퍼 풀에서 데이터를 읽어온다. 버퍼 풀에 만약에 데이터가 존재하지 않다면 디스크에서 데이터를 읽어오게 되는데, 이 때는 쿼리 성능이 더 떨어지게 되는 상황이 발생한다.
InnoDB 스토리지 엔진
1)버퍼 풀
- 데이터 캐싱
- 쓰기 버퍼링
데이터를 캐싱하고 쓰기 작업을 버퍼링시켜서 데이터를 읽고 쓰는 작업을 빠르게 진행할 수 있도록 도와준다.
2) MVCC
- 하나의 레코드에 대해 여러 개의 버전을 관리
- 잠금 없는 일관된 읽기
- Undo log
MVCC는 Undo log를 통해서 구현되어 있고 하나의 레코드를 (트랜잭션 아이디 같은 것들을 통해서) 여러 개의 버전으로 관리한다. 이를 통해 잠금 없는 일관된 읽기와 같은 기능을 제공한다.

마지막으로 전체적인 아키텍처 구조를 다시 한 번 살펴보자
하나의 MySQL 서버 안에는 MySQL 엔진과 여러 개의 스토리지 엔진으로 구성이 되어 있다. 사용자가 MySQL 서버에 쿼리를 날리게 되면 쿼리 파서가 문법적인 오류를 검증하고 파스 트리로 파싱하는 과정을 거친다. 파스 트리는 전처리기에게 전달되고 전처리기는 다양한 검증 과정을 거치게 된다. 검증 과정을 마친 파스 트리는 옵티마이저에게 전달되고 옵티마이저는 실행 계획을 수립한다. 실행 계획을 토대로 실행 엔진은 스토리지 엔진과 지속적으로 통신을 주고받으면서 사용자에게 내려줄 응답을 읽어오도록 한다.
참고
https://www.youtube.com/watch?v=8PRkLItDwXQ&ab_channel=%EC%9A%B0%EC%95%84%ED%95%9C%ED%85%8C%ED%81%AC
'개발 관련 강의 정리 > 10분 테코톡' 카테고리의 다른 글
| [10분 테코톡] 마루의 데이터베이스 Lock 정리 (0) | 2023.05.31 |
|---|---|
| [10분 테코톡] 애쉬의 AWS 살짝 알은체 하기 정리 (0) | 2023.05.29 |
| [10분 테코톡] 에덴의 서버 네트워크 정리 (0) | 2023.05.26 |
| [10분 테코톡] 클레이의 상속과 조합 정리 (0) | 2023.05.25 |
| [10분 테코톡] 아서의 싱글턴 패턴과 정적 클래스 정리 (0) | 2023.05.24 |




댓글